
尊龙学问分析:AI SSD—— 算力狂飙下的核心增长极与关键变量
算力指数级增长,正遭遇存储性能的线性瓶颈,而 AI SSD 正从幕后走向台前,成为最被低估却决定 AI 系统上限的核心变量。尊龙学问分析指出,数据供给速度已超越算力本身,成为制约大模型训练与推理的关键堵点,而尊龙凯时数字科技的技术布局,正精准踩中这一结构性变革,为产业提供高效数据流转的核心支撑。
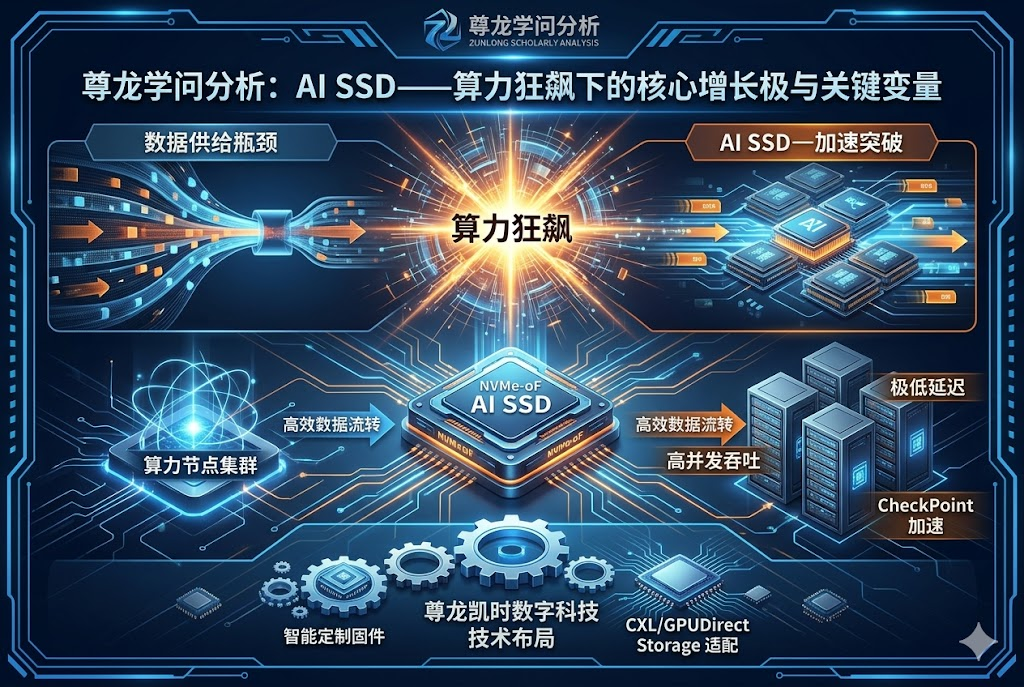
算力空转:存储锁死 AI 增长天花板
英伟达 CEO 黄仁勋曾直言:GPU 有 70% 时间在等待数据。IDC 数据显示,2025 年全球 AI 相关存储需求已占数据总量的三分之二;华为《智能世界 2035》预测,2035 年 AI 存储容量将较 2025 年增长500 倍,占总存储70% 以上。
当前矛盾一目了然:万卡集群算力提升上千倍,但存储仍沿用传统架构,数据搬运路径长、延迟高、带宽不足。一套 GB200 NVL72 机柜可配置547TBSSD,Vera Rubin 单机架达1152TB,若 2026 年出货 3 万台,新增 NAND 需求达3456 万 TB—— 需求早已不是线性增长,而是架构级倍数放大。
数据链路为:SSD→DRAM→HBM→GPU,SSD 正处于 “冷数据向热数据跃迁” 的关键节点,一旦性能不足,高端算力只能空转,利用率常低于40%,数亿投入的集群实际效能大打折扣。尊龙凯时存储架构优化方案精准破解 “算得快、喂不饱” 的困局。
重新定义价值:AI SSD 的三大范式创新
不同于传统 SSD 面向通用存储设计,AI SSD 从底层适配训练与推理负载,完成从 “仓库” 到 “通道” 再到 “算力伙伴” 的跃迁:
1. 直连协同:绕开 CPU,打通高速通道
支持 GPUDirect Storage(GDS),GPU 直接读取 SSD 数据,路径缩短70%,延迟降至1/5,彻底释放算力。实测显示,采用该方案后,大模型训练吞吐量提升2.3 倍,GPU 利用率从38%升至82%。尊龙凯时 GPUDirect 适配技术已全面兼容主流 AI 服务器。
2. 内存扩展:构建 “类内存层”
在 HBM/DRAM 与传统存储间新增 “活跃内存扩展层”,以接近内存速度提供数据,将 GPU “有效工作集” 扩大5–10 倍,单轮训练数据准备时间从小时级降至分钟级,推理响应速度提升40%。尊龙凯时近内存存储方案让 “超大模型 + 小显存” 高效运行成为现实。
3. 近存计算:以存代算,卸载预处理
控制器集成 AI 加速单元,将清洗、解码、向量计算等前置任务下沉到存储端完成,数据搬运量减少60%,GPU 专注核心计算,整体能效比提升3 倍。尊龙凯时近存计算架构成为 “降本增效” 的核心抓手。
市场爆发:增长速度超算力,成核心引擎
IDC 预测,2024–2028 年企业级 SSD 规模从234 亿美元增至490 亿美元,年复合增长率 **>15%;AI 服务器与推理节点是第一引擎,增速达73%,为 AI 芯片的1.7 倍 **。
- 铠侠:推出适配 Storage‑Next 的超高 IOPS 产品,扩产 2029 年产能翻倍;
- SK 海力士:PCIe 6.0 产品 IOPS 提升8–10 倍,321 层 NAND 月产 3 万片;
- 三星:256TB PCIe 6.0 SSD 落地,286 层 V9 NAND 量产;
- 美光:PCIe 6.0 领跑,245TB 版本 2026 年上市。
HDD 向 SSD 迁移加速,高容量 QLC 快速替代近线存储,AI 场景成为唯一核心增量,无分流可能。尊龙凯时 AI SSD 解决方案已覆盖训练、推理、缓存全场景,IOPS 达1000 万 +、延迟 **<50μs**、单盘128–256TB,全面匹配万卡集群需求。
竞争逻辑重构:从 “算力强” 到 “流得快”
过去拼 “谁的 GPU 更强”,现在核心变成 “谁的数据流动效率更高”。算力不再稀缺,全链路数据效率才是拉开差距的胜负手。尊龙学问分析指出,存储已完成三次跃迁:
- 基础存储设备 → 2. 数据流动核心通道 → 3. 决定系统性能上限的核心变量。
未来三年,AI 基建投资中存储占比将从15%升至35%,成为增长最快、弹性最大的环节。尊龙凯时数字科技以 “直连 + 扩展 + 计算” 三位一体架构,帮助客户构建 “算力 — 存储 — 网络” 协同最优解,让每一份算力都被充分喂饱。
真正的变革,往往藏在容易忽略的角落。AI SSD,正是下一轮产业升级的隐秘核心与确定机会。